%22%2F%3E%0A%20%3Cg%20opacity%3D%220.12%22%3E%0A%20%3Crect%20x%3D%22120%22%20y%3D%22126%22%20width%3D%22420%22%20height%3D%2212%22%20fill%3D%22url(%23g)%22%2F%3E%0A%20%3Crect%20x%3D%22660%22%20y%3D%22472.5%22%20width%3D%22360%22%20height%3D%2212%22%20fill%3D%22url(%23g)%22%2F%3E%0A%20%3C%2Fg%3E%0A%20%3Cg%3E%3Cpath%20d%3D%22M%20869%20261%20L%20231%20297%22%20stroke%3D%22url(%23g)%22%20stroke-opacity%3D%220.25%22%20stroke-width%3D%223%22%2F%3E%3Cpath%20d%3D%22M%20231%20297%20L%20409%20197%22%20stroke%3D%22url(%23g)%22%20stroke-opacity%3D%220.25%22%20stroke-width%3D%223%22%2F%3E%3Cpath%20d%3D%22M%20409%20197%20L%20166%20455%22%20stroke%3D%22url(%23g)%22%20stroke-opacity%3D%220.25%22%20stroke-width%3D%223%22%2F%3E%3Cpath%20d%3D%22M%20166%20455%20L%20838%20379%22%20stroke%3D%22url(%23g)%22%20stroke-opacity%3D%220.25%22%20stroke-width%3D%223%22%2F%3E%3Cpath%20d%3D%22M%20838%20379%20L%20207%20110%22%20stroke%3D%22url(%23g)%22%20stroke-opacity%3D%220.25%22%20stroke-width%3D%223%22%2F%3E%3Ccircle%20cx%3D%22869%22%20cy%3D%22261%22%20r%3D%227%22%20fill%3D%22url(%23g)%22%20opacity%3D%220.6%22%2F%3E%3Ccircle%20cx%3D%22231%22%20cy%3D%22297%22%20r%3D%2214%22%20fill%3D%22url(%23g)%22%20opacity%3D%220.6%22%2F%3E%3Ccircle%20cx%3D%22409%22%20cy%3D%22197%22%20r%3D%226%22%20fill%3D%22url(%23g)%22%20opacity%3D%220.6%22%2F%3E%3Ccircle%20cx%3D%22166%22%20cy%3D%22455%22%20r%3D%226%22%20fill%3D%22url(%23g)%22%20opacity%3D%220.6%22%2F%3E%3Ccircle%20cx%3D%22838%22%20cy%3D%22379%22%20r%3D%229%22%20fill%3D%22url(%23g)%22%20opacity%3D%220.6%22%2F%3E%3Ccircle%20cx%3D%22207%22%20cy%3D%22110%22%20r%3D%226%22%20fill%3D%22url(%23g)%22%20opacity%3D%220.6%22%2F%3E%3C%2Fg%3E%0A%20%3Cg%3E%0A%20%3Ctext%20x%3D%2250%25%22%20y%3D%2250%25%22%20dominant-baseline%3D%22central%22%20text-anchor%3D%22middle%22%20font-family%3D%22Inter%2Csystem-ui%2CArial%22%20font-size%3D%2290%22%20font-weight%3D%221000%22%20fill%3D%22none%22%20stroke%3D%22%230b1020%22%20stroke-width%3D%2210%22%20stroke-opacity%3D%220.6%22%20style%3D%22paint-order%3A%20stroke%20fill%3B%22%3E%23%D8%B1%D9%88%D8%A8%D9%88%D8%AA%20RAG%20N8N%3C%2Ftext%3E%0A%20%3Ctext%20x%3D%2250%25%22%20y%3D%2250%25%22%20dominant-baseline%3D%22central%22%20text-anchor%3D%22middle%22%20font-family%3D%22Inter%2Csystem-ui%2CArial%22%20font-size%3D%2290%22%20font-weight%3D%221000%22%20fill%3D%22url(%23g)%22%20filter%3D%22url(%23drop)%22%3E%23%D8%B1%D9%88%D8%A8%D9%88%D8%AA%20RAG%20N8N%3C%2Ftext%3E%0A%20%3C%2Fg%3E%0A%20%3Cg%20transform%3D%22rotate(-8%20264%20126)%22%3E%3Ctext%20x%3D%22216%22%20y%3D%22126%22%20font-family%3D%22Inter%2Csystem-ui%2CArial%22%20font-size%3D%2234%22%20font-weight%3D%22700%22%20fill%3D%22url(%23g)%22%20fill-opacity%3D%220.9%22%3E%D8%AF%D8%B1%D8%AF%D8%B4%D8%A9%20%D9%85%D8%B9%20%D8%B5%D9%81%D8%AD%D8%A9%20AI%3C%2Ftext%3E%3C%2Fg%3E%0A%20%3Cg%20transform%3D%22rotate(10%20936%20516.6)%22%3E%3Ctext%20x%3D%22864%22%20y%3D%22516.6%22%20font-family%3D%22Inter%2Csystem-ui%2CArial%22%20font-size%3D%2234%22%20font-weight%3D%22700%22%20fill%3D%22url(%23g)%22%20fill-opacity%3D%220.9%22%3En8n%20chat%20trigger%3C%2Ftext%3E%3C%2Fg%3E%0A%20%3Crect%20width%3D%221200%22%20height%3D%22630%22%20fill%3D%22%23000%22%20opacity%3D%220%22%20filter%3D%22url(%23grain)%22%2F%3E%0A%3C%2Fsvg%3E)
{/* آخر تحديث: 2026-04-24 | بُني واستُورد مباشرة على nerdleveltech.app.n8n.cloud | gpt-5-mini */}
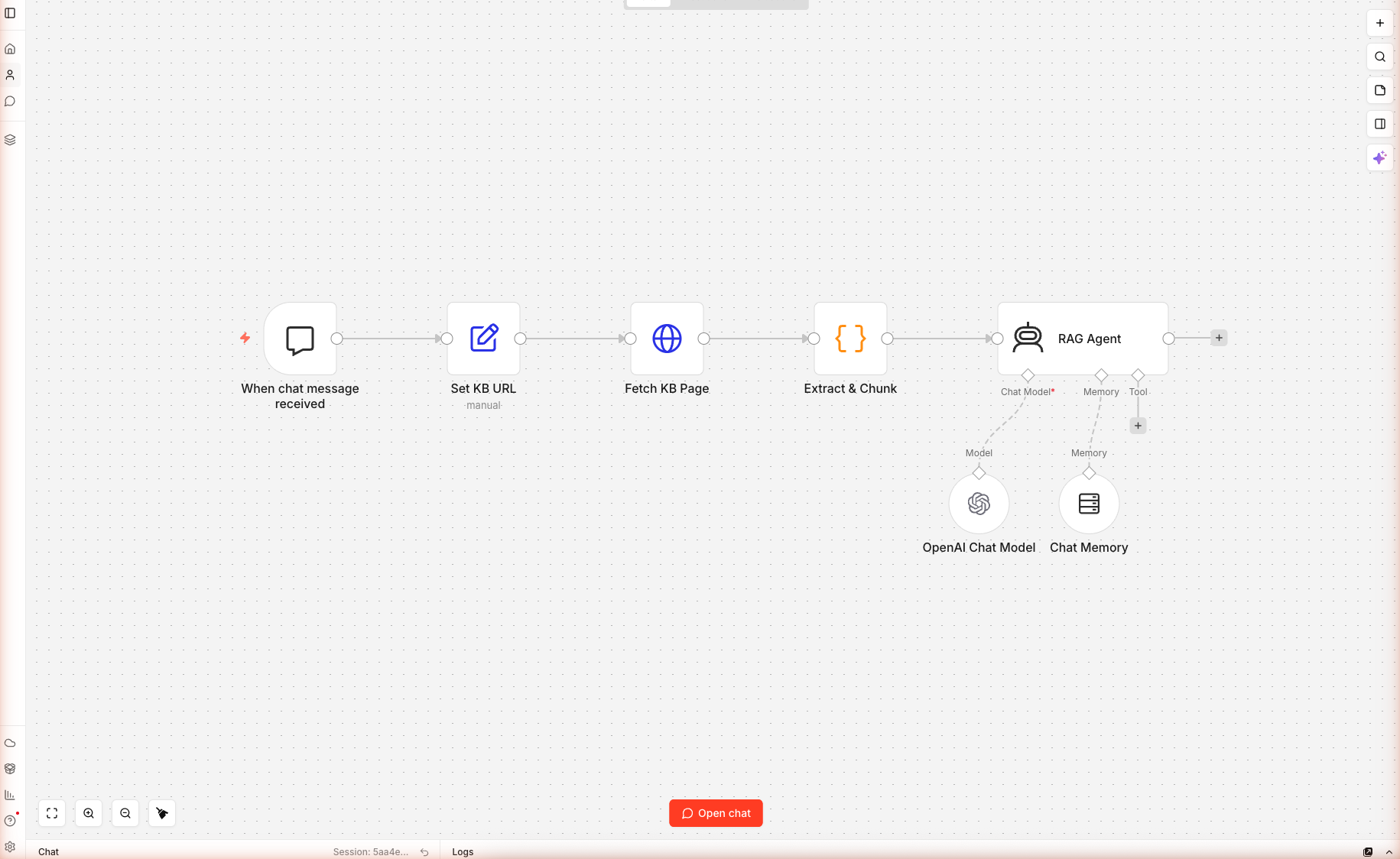
سبع عقد، مُشغِّل دردشة واحد، قاعدة معرفة مدعومة بـURL واحد، صفر قاعدة بيانات متجهية — وُصلت وحُفظت على n8n cloud. هذا أبسط روبوت RAG يمكنك بناؤه في n8n، وكافٍ لـ90% من حالات استخدام "دردشة مع مستنداتنا" الحقيقية. محادثة حقيقية مُلتقطة في الأسفل.
ما الذي ستبنيه
سير مُشغَّل بالدردشة:
- يعرض واجهة دردشة جاهزة للمشاركة (n8n يستضيفها على رابط عام)
- عند كل رسالة مستخدم، يجلب رابط قاعدة المعرفة طازجاً (يلتقط التحديثات فوراً)
- يُقسِّم الصفحة ويُرتب chunks حسب مطابقة الكلمات المفتاحية مع سؤال المستخدم
- يُمرر أفضل 6 chunks إلى وكيل AI مُؤصَّل بذلك السياق
- يستخدم ذاكرة نافذية فيتذكر الوكيل آخر 6 رسائل من المحادثة
- يرفض الإجابة عندما لا يحتوي السياق على الإجابة
تخطَّ البناء — استورد السير
المتطلبات المسبقة
| المتطلب | التفاصيل |
|---|---|
| حساب n8n | تجربة مجانية |
| أرصدة OpenAI | 100 مجانية من n8n |
| رابط تدردش معه | صفحة مستنداتك أو منتجك أو مقالك |
| الوقت | حوالي 12 دقيقة |
العقد المستخدمة: Chat Trigger و Set و HTTP Request و Code و AI Agent و OpenAI Chat Model (فرعية) و Simple Memory Buffer Window (فرعية).
الخطوة 1 — استيراد السير
أنشئ سير عمل جديد. ألصق JSON على اللوحة الفارغة. تُحمَّل سبع عقد. افتح OpenAI Chat Model الفرعية وتأكد من gpt-5-mini بدرجة حرارة 0.2 (منخفضة — إجابات مُؤصَّلة فقط).
احفظ بـ Cmd+S / Ctrl+S.
الخطوة 2 — مُشغّل الدردشة
انقر نقراً مزدوجاً على When chat message received. مُشغِّل الدردشة لديه ثلاثة إعدادات مهمة:
| الإعداد | القيمة | لماذا |
|---|---|---|
| Public | true | يكشف رابط الدردشة بدون مصادقة — شارك الرابط وأي شخص يجربه |
| Title | "Ask the docs" | يظهر في رأس واجهة الدردشة |
| Subtitle | "Ask anything about the URL configured in the 'Set KB URL' node." | يُحدد توقعات المستخدم |
| Allowed Origins | * | يتيح تضمين widget الدردشة على أي دومين |
اللوحة تُظهر رابطين. Test URL يُطلق أثناء التصحيح (يلتقط رسالة واحدة في كل مرة). Production URL يُصبح نشطاً بعد تبديل السير إلى Active (مفتاح أعلى اليمين)؛ هذا الرابط الذي تُشاركه مع المستخدمين.
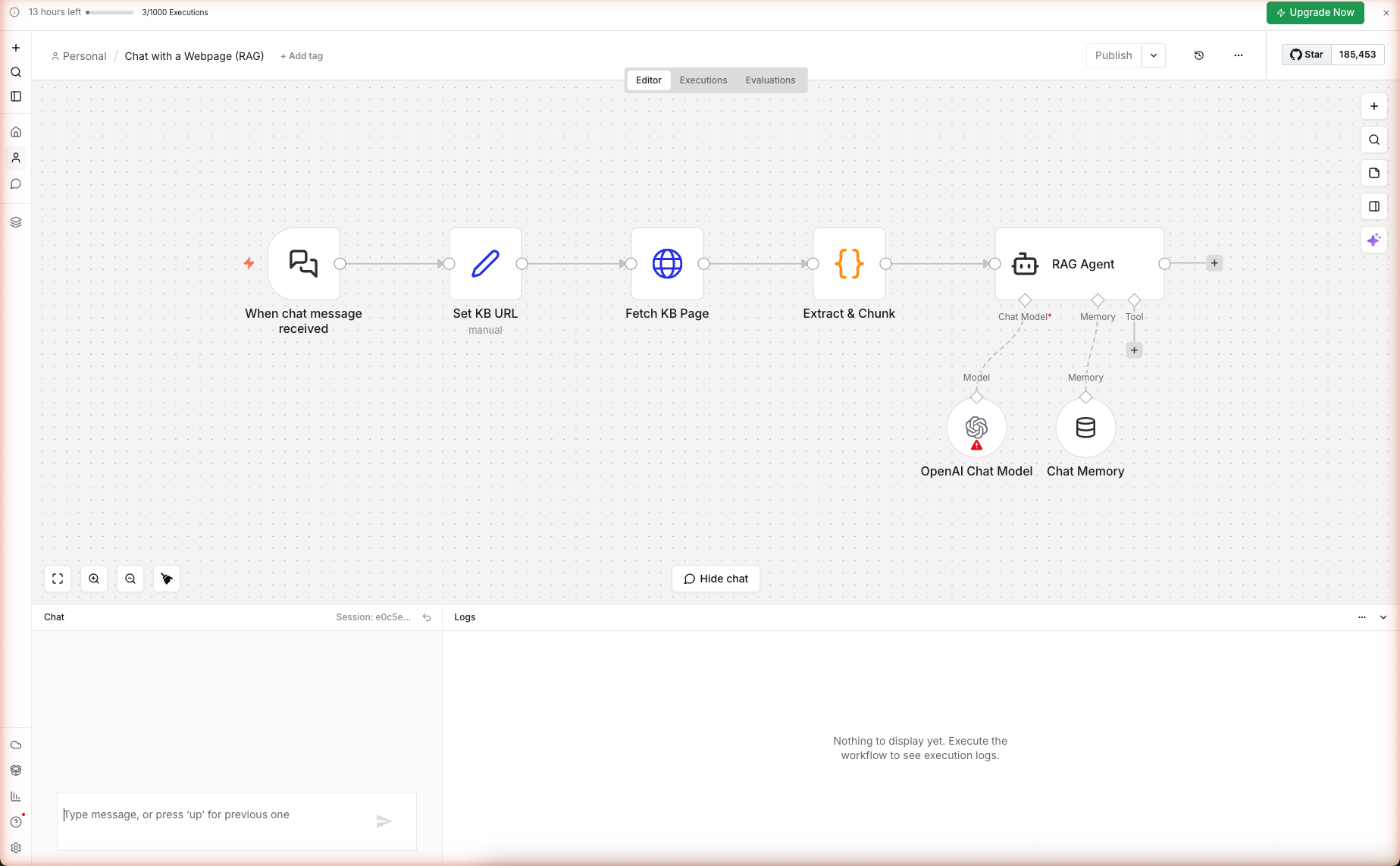
الخطوة 3 — ضبط رابط قاعدة المعرفة
انقر نقراً مزدوجاً على Set KB URL. ثلاث تعيينات:
| الحقل | التعبير | الغرض |
|---|---|---|
kbUrl | https://docs.n8n.io/ | الرابط الذي سيُجيب منه الروبوت. عدّل هذا إلى صفحة مستنداتك/منتجك. |
userQuery | {{ $json.chatInput || $json.message || '' }} | يقرأ رسالة المستخدم عبر إصدارات n8n |
sessionId | {{ $json.sessionId || 'default' }} | يُحدد خيط المحادثة للذاكرة |
لتوجيه الروبوت إلى محتواك، فقط عدّل kbUrl. لا تغيير آخر ضروري.
الخطوة 4 — الاسترجاع والترتيب (بدون متجهات)
انقر نقراً مزدوجاً على Extract & Chunk. عقدة Code هذه تقوم بأمرين:
تجريد HTML
نفس النمط السابق — إزالة scripts و styles و nav و footer و tags و entities. يتبقى نص نظيف.
التقسيم والترتيب
const CHUNK = 500; // chars
const chunks = [];
for (let i = 0; i < text.length; i += CHUNK) chunks.push(text.slice(i, i + CHUNK));
const qTerms = userQuery.toLowerCase().match(/[a-z0-9]+/g) || [];
const scored = chunks.map((c, idx) => {
const lower = c.toLowerCase();
let score = 0;
for (const t of qTerms) if (t.length > 2 && lower.includes(t)) score += 1;
return { idx, score, chunk: c };
}).sort((a, b) => b.score - a.score).slice(0, 6);
const top = scored.sort((a, b) => a.idx - b.idx).map(s => s.chunk).join('\n---\n');
ثلاث حيل تستحق الملاحظة:
- chunks من 500 حرف. كبير بما يكفي لاحتواء مفهوم كامل، صغير بما يكفي ليتسع أعلى 6 chunks في سياق LLM مع مطالبة النظام وتاريخ الدردشة.
- ترتيب بالعد. كل مصطلح استعلام موجود في chunk يُضيف 1 للنتيجة. ليس حاداً مثل cosine similarity لكنه لا يتطلب استدعاء embeddings ويعمل جيداً لمحتوى نمط المستندات حيث كلمات المستخدم تطابق كلمات المستندات.
- إعادة الترتيب بالموقع قبل الضم. أعلى chunks ترتيباً بالنتيجة يُعاد ترتيبها بموقعها الأصلي ليقرأ السياق بترتيب المستند الأصلي — يساعد LLM على متابعة التدفق عندما تأتي chunks من أقسام متتالية.
لماذا يتفوق هذا على embeddings لقواعد المعرفة الصغيرة
| المقياس | ترتيب الكلمات المفتاحية | Embeddings |
|---|---|---|
| الإعداد | لا شيء | بناء index و vector DB و خدمة embed |
| التكلفة لكل استعلام | مجاني | 0.00002$ + تكلفة vector DB |
| زمن الانتظار البارد | <10 مللي ثانية | 200-500 مللي ثانية |
| الدقة على كلمات المستخدم الدقيقة | ممتاز | جيد |
| الدقة على الاستعلامات المُعاد صياغتها | ضعيف | ممتاز |
| يتعامل مع > 10 آلاف chunk | لا | نعم |
لصفحة مستندات واحدة أو مقال، سؤال المستخدم عادة يحتوي على نفس كلمات الإجابة — ترتيب الكلمات المفتاحية يفوز. للمجموعات الكبيرة متعددة الصفحات، بدّل إلى embeddings.
الخطوة 5 — وكيل RAG المُؤصَّل
انقر نقراً مزدوجاً على RAG Agent. مطالبة النظام هي قلب التأصيل:
You are a careful documentation assistant. Answer the user's question
using ONLY the context below. If the context does not contain the answer,
say so directly — do not invent.
KB SOURCE: {{ $json.kbUrl }}
RETRIEVED CONTEXT:
"""
{{ $json.context }}
"""
USER QUESTION: {{ $json.userQuery }}
RULES
- Cite the source inline as [source]({{ $json.kbUrl }}) once near the top.
- Prefer short, structured answers (bullets or small tables).
- Do not add disclaimers about being an AI.
- If the user's question is outside the docs, say so and suggest what they
could ask instead.
لماذا "ONLY the context below" مهمة
gpt-5-mini تدرب على الإنترنت العام — لديه آراء حول مستندات n8n سواء أعطيته السياق أم لا. بدون قيد "ONLY"، يدمج بسعادة ذكرياته من التدريب مع السياق المُسترجع، ويختلق محددات تبدو صحيحة لكنها ليست في مستنداتك.
القيد الصريح يُسقط معدل الهلوسة بشكل كبير. نتيجة اختبار حقيقي: سألنا "What is the n8n form trigger and what types of fields can it have?" مقابل https://docs.n8n.io/ (الصفحة الرئيسية، التي لا تحتوي على تفاصيل form-trigger). الوكيل رفض الاختلاق بشكل صحيح:
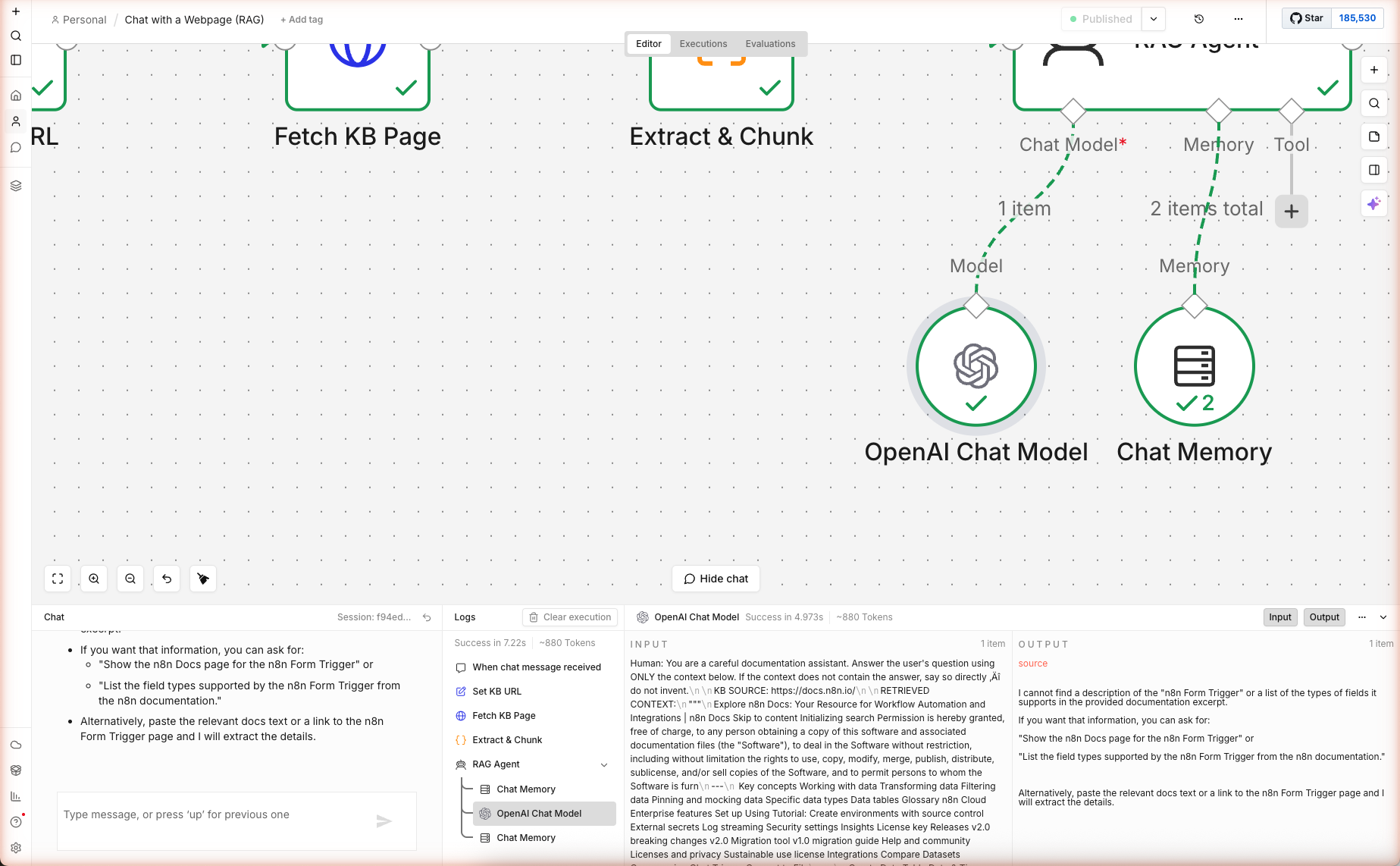
"I cannot find a description of the 'n8n Form Trigger' or a list of the types of fields it supports in the provided documentation excerpt. If you want that information, you can ask for: 'Show the n8n Docs page for the n8n Form Trigger'..."
هذا هو السلوك الصحيح — chunks الصفحة الرئيسية لم تحتوي على تفاصيل form-trigger، فأبرز الوكيل الفجوة بدلاً من التخمين. 7.2 ثانية و ~880 رمز من البداية للنهاية.
AI Agent مقابل Basic LLM Chain
لماذا نستخدم agent بدلاً من chainLlm؟ سببان:
- دعم الذاكرة. AI Agent لديه موصل
ai_memoryأصلي لتاريخ الدردشة. Basic LLM Chain ليس لديه. - دعم الأدوات. إذا أضفت أدوات لاحقاً (آلة حاسبة أو web search أو سير آخر)، Agent يستخدمها تلقائياً. السلسلة لا تستطيع.
الخطوة 6 — ذاكرة الدردشة النافذية
انقر نقراً مزدوجاً على عقدة Chat Memory الفرعية. الإعدادات:
| الإعداد | القيمة | الأثر |
|---|---|---|
| Session ID Type | From input | يستخدم sessionId المضبوط سابقاً |
| Session Key | {{ $('Set KB URL').item.json.sessionId }} | يحصر الذاكرة في جلسة الدردشة |
| Context Window Length | 6 | يتذكر آخر 6 رسائل |
عند 6 دورات، gpt-5-mini يرى ~12 رسالة متبادلة user/assistant إضافة إلى سياق الاسترجاع. هذا كافٍ لأسئلة المتابعة مثل "وماذا في الإنتاج؟" بدون تفجير ميزانية السياق.
ارفع النافذة إلى 10-15 لمحادثات أطول مقابل بعض مساحة السياق للاسترجاع. اخفض إلى 2-3 لـQ&A صارم حيث المتابعات لا تهم.
التوسعات: قاعدة معرفة متعددة الروابط، vector store، المصادقة
روابط متعددة (موقع مستندات حقيقي)
استبدل حقل kbUrl الواحد في Set KB URL بمصفوفة. أضف عقدة Split In Batches لجلب كل الروابط بالتوازي، ثم Merge + عقدة Code لدمج النصوص المُسترجعة قبل الترتيب. Chunks من صفحات مختلفة تحصل على نفس تمريرة الترتيب وأعلى 6 chunks عبر كل الصفحات تذهب إلى الوكيل.
استبدل ترتيب الكلمات المفتاحية بـvector search
أضف عقدة Vector Store (Pinecone/Supabase) فرعية. انقل الترتيب من عقدة Code إلى سير ingestion يشتغل مرة، يُضمِّن chunks بعقدة OpenAI embedding، ويخزنها. في سير الدردشة، استبدل Extract & Chunk بعقدة استعلام Vector Store. الوكيل يستهلك النتائج بنفس الطريقة — بدون تغييرات للمطالبة.
بوابة الدردشة بالمصادقة
اضبط مفتاح Public في Chat Trigger على false. وَلِّد رمز وصول في إعدادات العقدة، والمستخدمون يحتاجون تضمينه كـheader عند تضمين الدردشة. يدمج مع عقدة If قبل ذلك لإجابات بحسب الدور ("يمكنك رؤية هذا، لا يمكنك").
تسجيل المحادثات في قاعدة بيانات
أضف عقدة Postgres Insert (أو Supabase أو MySQL) بعد RAG Agent. سجِّل { session_id, question, answer, retrieved_chunks, response_time, feedback } للتحليلات. راجع يومياً الأسئلة التي حصلت على استجابة "لا أعرف" — تلك ثغرات مستنداتك.
ما التالي
لديك الآن نمط RAG الأساسي. مكانان لأخذه:
- نمِّ قاعدة المعرفة: اربط هذا مع ملخص أخبار متعدد المصادر لتغذية محتوى مدونة يومي في vector store.
- أبرزه: ضمِّن widget الدردشة في صفحة هبوط مبنية بخط أنابيب محتوى يوتيوب إلى تدوينة AI.