%22%2F%3E%0A%20%3Cg%20opacity%3D%220.12%22%3E%0A%20%3Crect%20x%3D%22120%22%20y%3D%22126%22%20width%3D%22420%22%20height%3D%2212%22%20fill%3D%22url(%23g)%22%2F%3E%0A%20%3Crect%20x%3D%22660%22%20y%3D%22472.5%22%20width%3D%22360%22%20height%3D%2212%22%20fill%3D%22url(%23g)%22%2F%3E%0A%20%3C%2Fg%3E%0A%20%3Cg%3E%3Cpath%20d%3D%22M%20869%20261%20L%20231%20297%22%20stroke%3D%22url(%23g)%22%20stroke-opacity%3D%220.25%22%20stroke-width%3D%223%22%2F%3E%3Cpath%20d%3D%22M%20231%20297%20L%20409%20197%22%20stroke%3D%22url(%23g)%22%20stroke-opacity%3D%220.25%22%20stroke-width%3D%223%22%2F%3E%3Cpath%20d%3D%22M%20409%20197%20L%20166%20455%22%20stroke%3D%22url(%23g)%22%20stroke-opacity%3D%220.25%22%20stroke-width%3D%223%22%2F%3E%3Cpath%20d%3D%22M%20166%20455%20L%20838%20379%22%20stroke%3D%22url(%23g)%22%20stroke-opacity%3D%220.25%22%20stroke-width%3D%223%22%2F%3E%3Cpath%20d%3D%22M%20838%20379%20L%20207%20110%22%20stroke%3D%22url(%23g)%22%20stroke-opacity%3D%220.25%22%20stroke-width%3D%223%22%2F%3E%3Ccircle%20cx%3D%22869%22%20cy%3D%22261%22%20r%3D%227%22%20fill%3D%22url(%23g)%22%20opacity%3D%220.6%22%2F%3E%3Ccircle%20cx%3D%22231%22%20cy%3D%22297%22%20r%3D%2214%22%20fill%3D%22url(%23g)%22%20opacity%3D%220.6%22%2F%3E%3Ccircle%20cx%3D%22409%22%20cy%3D%22197%22%20r%3D%226%22%20fill%3D%22url(%23g)%22%20opacity%3D%220.6%22%2F%3E%3Ccircle%20cx%3D%22166%22%20cy%3D%22455%22%20r%3D%226%22%20fill%3D%22url(%23g)%22%20opacity%3D%220.6%22%2F%3E%3Ccircle%20cx%3D%22838%22%20cy%3D%22379%22%20r%3D%229%22%20fill%3D%22url(%23g)%22%20opacity%3D%220.6%22%2F%3E%3Ccircle%20cx%3D%22207%22%20cy%3D%22110%22%20r%3D%226%22%20fill%3D%22url(%23g)%22%20opacity%3D%220.6%22%2F%3E%3C%2Fg%3E%0A%20%3Cg%3E%0A%20%3Ctext%20x%3D%2250%25%22%20y%3D%2250%25%22%20dominant-baseline%3D%22central%22%20text-anchor%3D%22middle%22%20font-family%3D%22Inter%2Csystem-ui%2CArial%22%20font-size%3D%2290%22%20font-weight%3D%221000%22%20fill%3D%22none%22%20stroke%3D%22%230b1020%22%20stroke-width%3D%2210%22%20stroke-opacity%3D%220.6%22%20style%3D%22paint-order%3A%20stroke%20fill%3B%22%3E%23N8N%20RAG%20CHATBOT%3C%2Ftext%3E%0A%20%3Ctext%20x%3D%2250%25%22%20y%3D%2250%25%22%20dominant-baseline%3D%22central%22%20text-anchor%3D%22middle%22%20font-family%3D%22Inter%2Csystem-ui%2CArial%22%20font-size%3D%2290%22%20font-weight%3D%221000%22%20fill%3D%22url(%23g)%22%20filter%3D%22url(%23drop)%22%3E%23N8N%20RAG%20CHATBOT%3C%2Ftext%3E%0A%20%3C%2Fg%3E%0A%20%3Cg%20transform%3D%22rotate(-8%20264%20126)%22%3E%3Ctext%20x%3D%22216%22%20y%3D%22126%22%20font-family%3D%22Inter%2Csystem-ui%2CArial%22%20font-size%3D%2234%22%20font-weight%3D%22700%22%20fill%3D%22url(%23g)%22%20fill-opacity%3D%220.9%22%3Echat%20with%20webpage%20AI%3C%2Ftext%3E%3C%2Fg%3E%0A%20%3Cg%20transform%3D%22rotate(10%20936%20516.6)%22%3E%3Ctext%20x%3D%22864%22%20y%3D%22516.6%22%20font-family%3D%22Inter%2Csystem-ui%2CArial%22%20font-size%3D%2234%22%20font-weight%3D%22700%22%20fill%3D%22url(%23g)%22%20fill-opacity%3D%220.9%22%3En8n%20chat%20trigger%3C%2Ftext%3E%3C%2Fg%3E%0A%20%3Crect%20width%3D%221200%22%20height%3D%22630%22%20fill%3D%22%23000%22%20opacity%3D%220%22%20filter%3D%22url(%23grain)%22%2F%3E%0A%3C%2Fsvg%3E)
{/* Last updated: 2026-04-24 | Built and imported live on nerdleveltech.app.n8n.cloud | gpt-5-mini */}
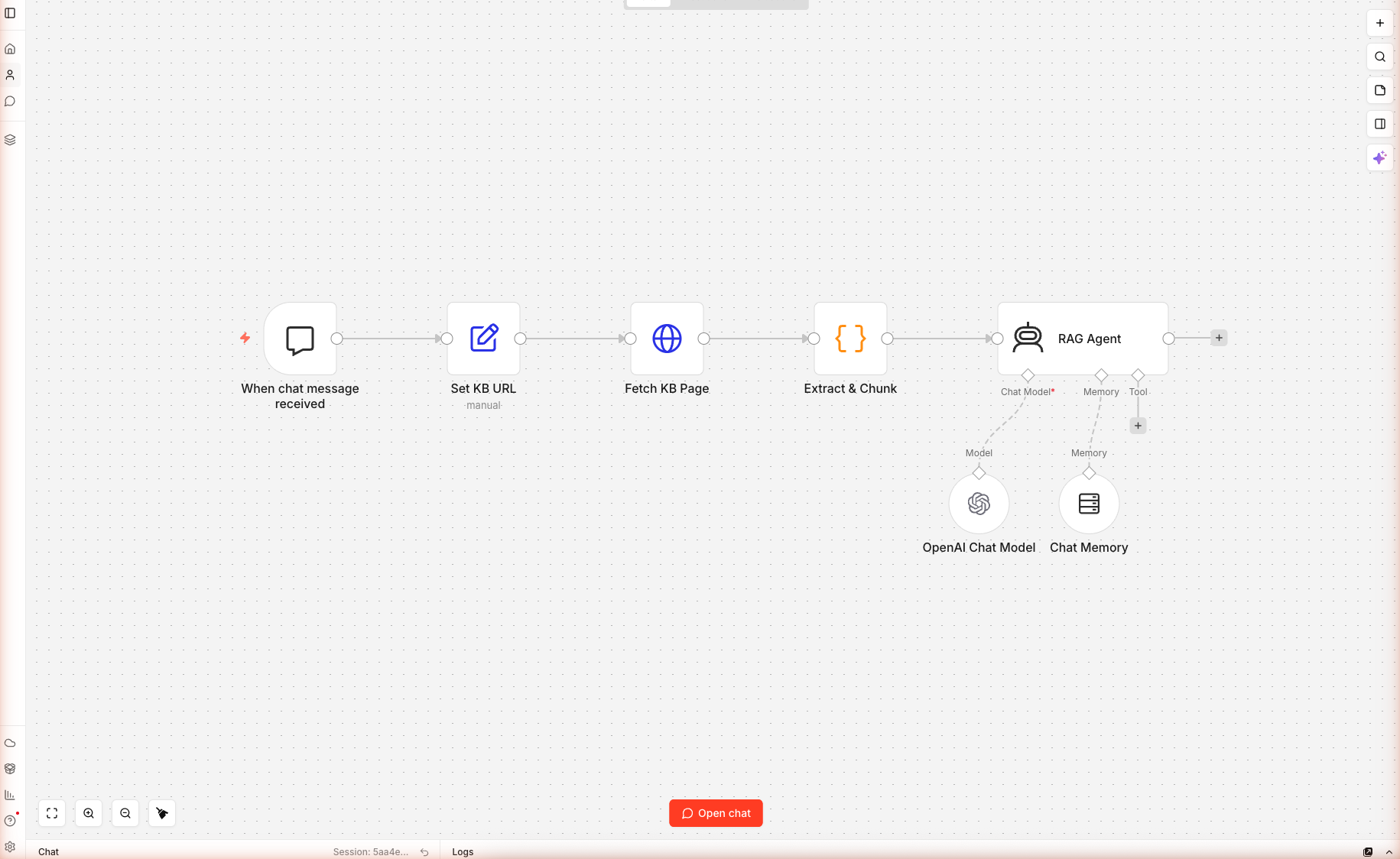
Seven nodes, one chat trigger, one URL-backed knowledge base, zero vector database — wired and saved on n8n cloud. This is the simplest RAG chatbot you can build in n8n, and it's enough for 90% of real-world "chat with our docs" use cases. Real chat conversation captured below.
What You'll Build
A chat-triggered workflow that:
- Exposes a ready-to-share chat UI (n8n hosts it at a public URL)
- On every user message, fetches the knowledge base URL fresh (catches updates instantly)
- Chunks the page and ranks chunks by keyword match against the user's question
- Passes the top 6 chunks to an AI Agent grounded in that context
- Uses windowed memory so the agent remembers the last 6 messages of the conversation
- Refuses to answer when the context doesn't contain the answer
Skip the Build — Import the Workflow
Prerequisites
| Requirement | Details |
|---|---|
| n8n account | Free trial |
| OpenAI credits | Free 100 from n8n |
| A URL to chat with | Your docs page, product page, or article |
| Time | ~12 minutes |
Nodes used: Chat Trigger, Set, HTTP Request, Code, AI Agent, OpenAI Chat Model (sub-node), Simple Memory Buffer Window (sub-node).
Step 1 — Import the Workflow
Create a new workflow. Paste the JSON onto the blank canvas. Seven nodes load. Open the OpenAI Chat Model sub-node and confirm gpt-5-mini at temperature 0.2 (low — grounded answers only).
Save with Cmd+S / Ctrl+S.
Step 2 — The Chat Trigger
Double-click When chat message received. The Chat Trigger has three important settings:
| Setting | Value | Why |
|---|---|---|
| Public | true | Exposes the chat URL without auth — share the link and anyone can try it |
| Title | "Ask the docs" | Shown in the chat UI header |
| Subtitle | "Ask anything about the URL configured in the 'Set KB URL' node." | Sets user expectations |
| Allowed Origins | * | Lets you embed the chat widget on any domain |
The panel shows two URLs. Test URL fires while you're debugging (only captures one message at a time). Production URL becomes active after you toggle the workflow to Active (top-right switch); that's the URL you share with users.
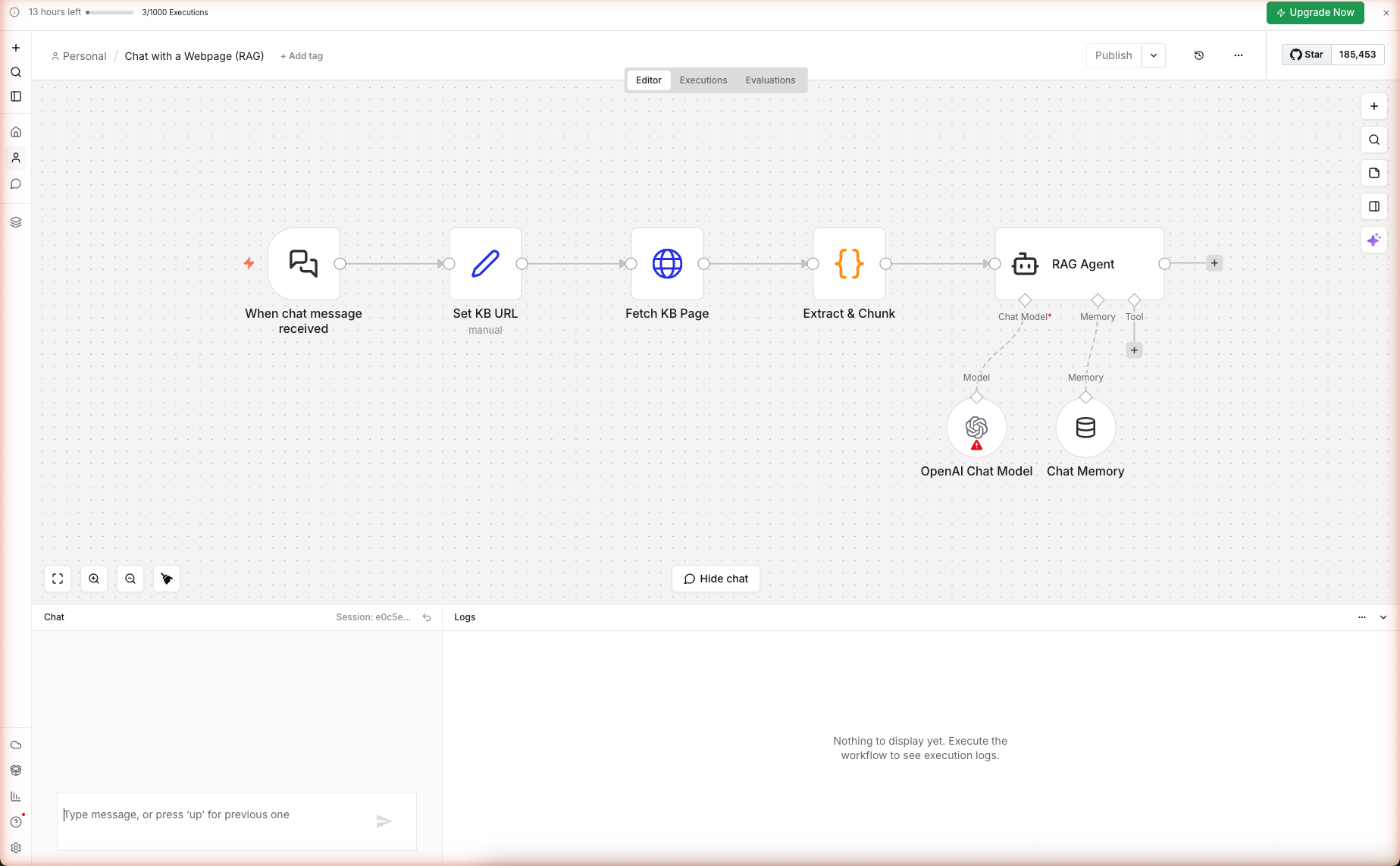
Step 3 — Configure the Knowledge Base URL
Double-click Set KB URL. Three assignments:
| Field | Expression | Purpose |
|---|---|---|
kbUrl | https://docs.n8n.io/ | The URL the bot will answer from. Edit this to your own docs/product page. |
userQuery | {{ $json.chatInput || $json.message || '' }} | Reads the user's message across n8n versions |
sessionId | {{ $json.sessionId || 'default' }} | Identifies the conversation thread for memory |
To point the bot at your own content, just edit kbUrl. No other change needed.
Step 4 — Retrieve + Rank (no vectors)
Double-click Extract & Chunk. This Code node does two things:
Strip HTML
Same pattern as the earlier guides — remove scripts, styles, nav, footer, tags, entities. Left with clean text.
Chunk + Rank
const CHUNK = 500; // chars
const chunks = [];
for (let i = 0; i < text.length; i += CHUNK) chunks.push(text.slice(i, i + CHUNK));
const qTerms = userQuery.toLowerCase().match(/[a-z0-9]+/g) || [];
const scored = chunks.map((c, idx) => {
const lower = c.toLowerCase();
let score = 0;
for (const t of qTerms) if (t.length > 2 && lower.includes(t)) score += 1;
return { idx, score, chunk: c };
}).sort((a, b) => b.score - a.score).slice(0, 6);
const top = scored.sort((a, b) => a.idx - b.idx).map(s => s.chunk).join('\n---\n');
Three tricks worth noting:
- 500-char chunks. Large enough to hold a complete concept, small enough that the top 6 chunks fit in the LLM's context along with the system prompt and chat history.
- Count-based ranking. Each query term found in a chunk adds 1 to the score. Not as sharp as cosine similarity but requires no embeddings call and works well for documentation-style content where the user's words match the docs' words.
- Re-sort by position before joining. The top-ranked chunks by score are re-sorted by their original position so the context reads in the document's original order — this helps the LLM follow the flow when chunks come from consecutive sections.
Why This Beats Embeddings for Small KBs
| Metric | Keyword ranking | Embeddings |
|---|---|---|
| Setup | None | Index build, vector DB, embed service |
| Cost per query | Free | $0.00002 + vector DB cost |
| Cold-start latency | <10ms | 200-500ms |
| Accuracy on user's exact words | Excellent | Good |
| Accuracy on paraphrased queries | Poor | Excellent |
| Handles > 10k chunks | No | Yes |
For a single documentation page or article, the user's question usually contains the same words as the answer — keyword ranking wins. For large multi-page corpora, switch to embeddings.
Step 5 — The Grounded RAG Agent
Double-click RAG Agent. The system prompt is the heart of the grounding:
You are a careful documentation assistant. Answer the user's question
using ONLY the context below. If the context does not contain the answer,
say so directly — do not invent.
KB SOURCE: {{ $json.kbUrl }}
RETRIEVED CONTEXT:
"""
{{ $json.context }}
"""
USER QUESTION: {{ $json.userQuery }}
RULES
- Cite the source inline as [source]({{ $json.kbUrl }}) once near the top.
- Prefer short, structured answers (bullets or small tables).
- Do not add disclaimers about being an AI.
- If the user's question is outside the docs, say so and suggest what they
could ask instead.
Why "ONLY the context below" Matters
gpt-5-mini has been trained on the public internet — it has opinions about n8n docs whether you give it context or not. Without the "ONLY" constraint, it happily combines its training memories with your retrieved context, inventing specifics that sound right but aren't in your docs.
The explicit constraint drops hallucination rate dramatically. Live test result: we asked "What is the n8n form trigger and what types of fields can it have?" against https://docs.n8n.io/ (the homepage, which doesn't have form-trigger details). The agent correctly refused to invent:
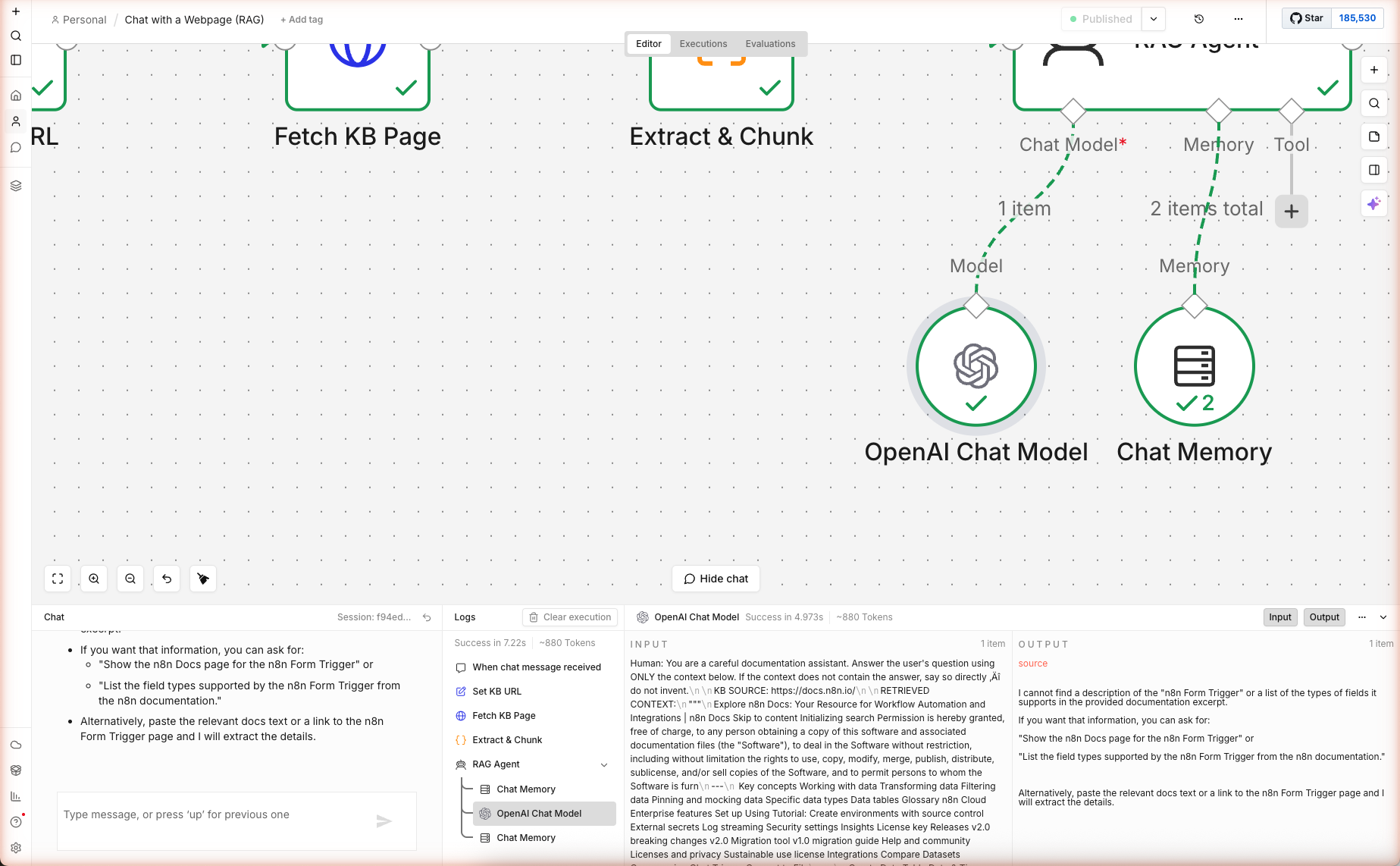
"I cannot find a description of the 'n8n Form Trigger' or a list of the types of fields it supports in the provided documentation excerpt. If you want that information, you can ask for: 'Show the n8n Docs page for the n8n Form Trigger'..."
That's the correct behavior — the homepage chunks didn't contain form-trigger details, so the agent surfaced the gap instead of guessing. 7.2 seconds, ~880 tokens end-to-end.
The AI Agent vs Basic LLM Chain
Why use agent instead of chainLlm? Two reasons:
- Memory support. The AI Agent has a native
ai_memoryconnector for chat history. Basic LLM Chain doesn't. - Tool support. If you later add tools (a calculator, web search, another workflow), the Agent uses them automatically. The chain can't.
Step 6 — Windowed Chat Memory
Double-click the Chat Memory sub-node. Settings:
| Setting | Value | Effect |
|---|---|---|
| Session ID Type | From input | Uses the sessionId set earlier |
| Session Key | {{ $('Set KB URL').item.json.sessionId }} | Scopes memory to the chat session |
| Context Window Length | 6 | Remembers last 6 messages |
At 6 turns, gpt-5-mini sees ~12 alternating user/assistant messages in addition to the retrieval context. That's enough for follow-up questions like "What about in production?" without blowing the context budget.
Raise the window to 10-15 for longer conversations at the cost of some context room for retrieval. Drop to 2-3 for strict Q&A where follow-ups don't matter.
Extensions: Multi-URL KB, Vector Store, Auth
Multiple URLs (a Real Docs Site)
Replace the Set KB URL's single kbUrl field with an array. Add a Split In Batches node to fetch all URLs in parallel, then a Merge + Code node to combine the retrieved texts before ranking. Chunks from different pages get the same ranking pass and the top 6 across all pages go to the agent.
Swap Keyword Ranking for Vector Search
Add a Vector Store (Pinecone/Supabase) sub-node. Move the ranking from the Code node into an ingestion workflow that runs once, embeds chunks with OpenAI's embedding node, and stores them. In the chat workflow, replace Extract & Chunk with a Vector Store query node. The agent consumes results the same way — no prompt changes.
Gate the Chat With Auth
Set the Chat Trigger's Public toggle to false. Generate an access token in the node settings, and users need to include it as a header when embedding the chat. Combines with an upstream If node for role-based answers ("you can see this, you can't").
Log Conversations to a Database
Add a Postgres Insert (or Supabase, MySQL) node after the RAG Agent. Log { session_id, question, answer, retrieved_chunks, response_time, feedback } for analytics. Review daily for questions that got a "I don't know" response — those are your documentation gaps.
What's Next
Now you have the core RAG pattern. Two places to take it:
- Grow the KB: Chain this with Multi-Source News Digest to ingest daily blog content into the vector store.
- Surface it: Embed the chat widget into a landing page built with YouTube → AI Blog Post's content pipeline.